SwinDeW-G
(Swinburne Decentralised Workflow for Grid)
[Overall System Architecture]
Contact:
Dr. Jinjun Chen: jchen@ict.swin.edu.au
Prof. Yun Yang: yyang@ict.swin.edu.au
Content
5. Uploading and Enacting Processes
1. Introduction
SwinDeW-G (Swinburne Decentralised Workflow for Grid) is a grid workflow management system running on GT4 compatible grid infrastructures or testbeds. It combines p2p (peer to peer) and grid technologies to simulate the enactment of business processes in a decentralised manner. This prototype functions using the JXTA platform (www.jxta.org) for p2p and the Globus Toolkit for grid.
This report is intended to provide an explanation of how to use and develop on SwinDeW-G. It is assumed that the reader has a basic understanding of workflow and process enacting.
2. Requirements
Before commencing it is required that SwinDeW-G and its related software is installed. An explanation of how to do this is available in the SwinDeW-G Setup Guide, http://www.swinflow.org/docs/Setup_Manual.pdf.
3. System Architecture
The overall system architecture is depicted in Fig. 1 below. The following sub-sections will describe each of these layers in more detail. As we can see, SwinDeW-G sits on a grid infrastructure named SwinGrid (Swinburne Grid).
|
Grid Workflow Applications |
|
|
SwinDeW-G |
|
|
Core Grid Middleware (GT4, CROWN) |
SwinGrid Infrastructure |
|
OS, Software (Windows Linux) |
|
|
Hardware (High performance computers, 2.0 Tera FLOPS supercomputers) |
Fig. 1. Overall System Architecture of SwinDeW-G Environment
3.1 SwinGrid
An overall picture of SwinGrid is depicted in Fig. 2 which contains many grid nodes distributed in different places. Each grid node contains many computers including high performance PCs and/or supercomputers composed of many computing units. The primary hosting nodes include the Swinburne CITR (Centre for Information Technology Research) Node, Swinburne ESR (Enterprise Systems Research laboratory) Node, Swinburne Astrophysics Supercomputer Node, and Beihang CROWN Node in China. They are running Linux, GT (Globus Toolkit) 4.04 or CROWN grid toolkits 2.5 where CROWN (China R&D Environment Over Wide-area Network) is an extension of GT4 with more middleware, hence compatible with GT4. Besides, the CROWN Node is also connected to some other nodes such as those in Hong Kong University of Science and Technology, and University of Leeds in UK. The Swinburne Astrophysics Supercomputer Node is cooperating with APAC (Australian Partnership for Advanced Computing), VPAC (Victorian Partnership for Advanced Computing) and so on.
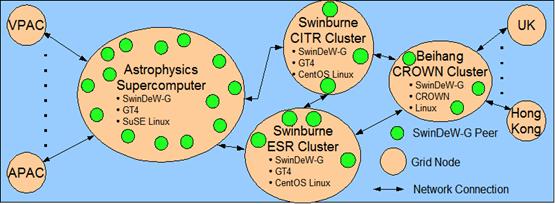
Fig. 2. Physical Network Layout of SwinGrid
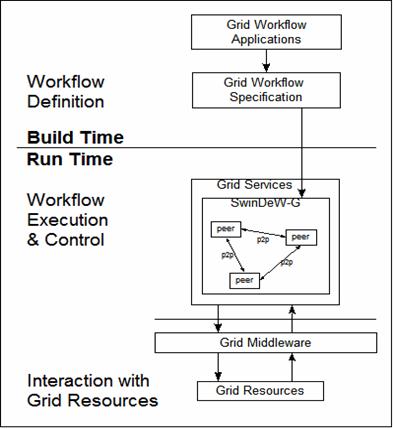
Fig. 3. Structure of SwinDeW-G
3.2 SwinDeW-G
Currently, SwinDeW-G is deployed at all primary hosting nodes in Fig. 2. It is planned to extend to other nodes in the near future. SwinDeW-G is a peer-to-peer based grid workflow management system. A grid workflow is executed by different peers that can be distributed at different grid nodes. Different peers communicate with each other directly in a peer-to-peer fashion. As shown in Fig. 2, each grid node can have a number of peers. A peer can be simply viewed as a capable grid service.
The detailed structure of SwinDeW-G is depicted in Fig. 3. At build-time, grid workflow specifications are defined. Then, at run-time, they are executed by different peers which facilitate the computing and resource sharing power of underlying grid infrastructure - SwinGrid.
3.3 Sample Grid Workflow Execution in SwinDeW-G
Fig. 4 shows a sample grid workflow execution in SwinDeW-G. Grid workflow activities are executed by different peers located in different grid nodes.
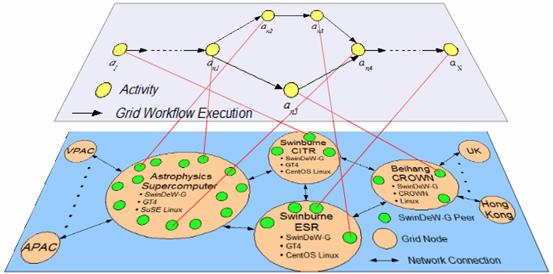
Fig. 4. Sample Grid Workflow Execution in SwinDeW-G Environment
When a grid workflow is executed, each activity is assigned to a peer. This assignment is based on which peer is the most suitable to execute the activity. To be suitable the peer must first be capable of executing that activity and not be busy with other tasks. Once all the activities have been assigned to a peer, the grid workflow is then executed from start to finish. Each peer that has a task assigned to it will communicate with the other peers so that the grid workflow executes in the correct order.
4. Launching Peers
4.1. SwinDeW-G Client
SwinDeW-G peers can be launched automatically via a java client. This client is located in the ‘clients’ directory under the name … . The running of this client executes the shell script … When used it allows the user to easily launch any number of peers via a GUI shown in Fig. 5.
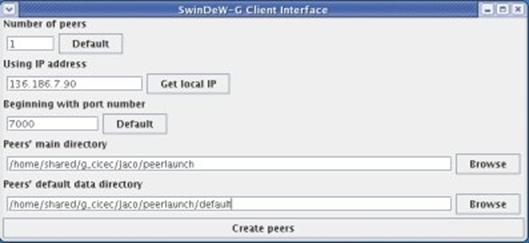
Fig. 5. The SwinDeW-G peer launching client
- Number of peers – This defines how many peers will be launched. Each peer will be opened in its own command window. For a standard desktop computer it is recommend that no more then 6 peers be launched. Exceeding this number will result in severe system slow down and a possible crash.
- Using IP Address - This is the IP address that the launched peers will use. This should be the IP address of the computer that the peers are launched on. Clicking the ‘Get local IP’ button will automatically detect the computer’s IP address.
- Beginning with port number – The first port that will be assigned. Each peer requires 2 ports. The first port is for the globus container and the second is for the JXTA p2p communications. Even ports will be assigned to the container while odds are assigned to p2p. Ports will be assigned incrementally starting from the one that is specified.
Note: Please ensure that the ports that SwinDeW-G uses are not blocked by a local firewall. They need to be open for communication on the local machine.
- Peers’ main directory – This directory will be used to store data about the peers. Each peer will have its own directory. A description of the files and uses of the peer directory can be found in the following section.
- Peers’ default directory – This is the directory that contains the default setup files for each peer. A description of this can be found in the following section.
When the ‘Create peers’ button is pressed a data directory will be created for each peer. These peers will then load within their own command window. This command window will display an output of the peer’s actions. A description of this output can be found in section 5.
4.2. Directory Structure
Each peer will automatically have a directory created for it. The peer uses this directory to access its configuration and capabilities files and to cache data for JXTA communication. When the ‘Create peers’ button is pressed, the program creates a unique directory for each peer and then copies the files from the ‘defaults’ directory into it. The data directories are only created for peers that do not already have one. In other words if peer1 already has a data directory containing its configuration files then no changes will be made to it when peer’s are launched.
The file ‘platformConfig’ is the configuration file for JXTA. JXTA uses this to get information about the peer before it loads. This information includes the peer’s name, ip address, port and login data. The SwinDeW-G client modifies the ‘platformConfig’ file for each peer to dynamically set their configuration data based upon the user input.
The file ‘log4j.properties’ configures how the output will be displayed.
4.3. Configuring Capabilities
Another file that is copied into each peer’s data directory is ‘capabilities.xml’. This file contains a list of the capabilities that the peer will have. By default each peer will be assigned all the capabilities in the Cheque Processing workflow. These are Scan Cheque, Analyse Image and Access Accounts.
To further experiment with SwinDeW-G it is possible to limit or change the capabilities that each peer has. This can be done by modifying ‘capabilities.xml’ and reloading the peer.
5. Uploading and Enacting Processes
The SwinDeW-G client is also able to upload and enact workflow processes. This can be done once a number of peers have been launched.
5.1. Client GUI
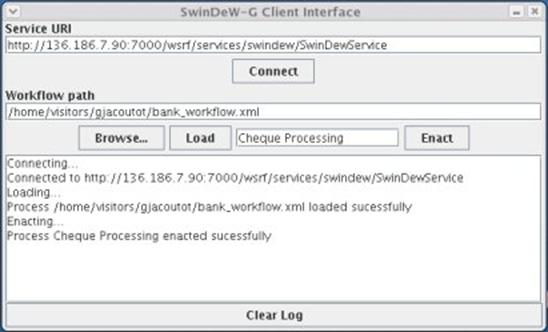
Fig. 6. The SwinDeW-G Workflow Process Client
- Service URI – As shown in Fig. 6, this is the URI of the peer that you want to upload and/or enacted a process on. The URI can be found in the peer’s command window when globus loads. The default URI will be that of the first peer that is loaded. Once the URI has been entered click connect to establish a connection to this peer. If the URI is invalid or the peer can not be located, then an error message will be displayed in the output window.
- Workflow path – This is the where the xml workflow file is located on the local machine. The browse button will open a file browser window to locate the file. The load button will upload the workflow to the connected peer. When a peer receives a workflow file, it will distribute the tasks in the workflow to peers that have the correct capabilities. Included with the SwniDeW-G distribution is ‘bank_workflow.xml’ which is located in the ‘client’ directory.
- Enact process – To enact a process on the connected peer, type in the name of the process and press the ‘Enact’ button. This peer will then try to locate this process and enact it. The process in the ‘bank_workflow.xml’ file is ‘Cheque Processing’.
- Output textbox – This shows the of the different actions performed within the process client. To clear the text simply press the ‘Clear log’ button.
6. SwinDeW-G Output
Each SwinDeW-G peer will have its own command window. This window will show the output from the different tasks that the peer is performing. An example of this output is shown below.
6.1. Output Description
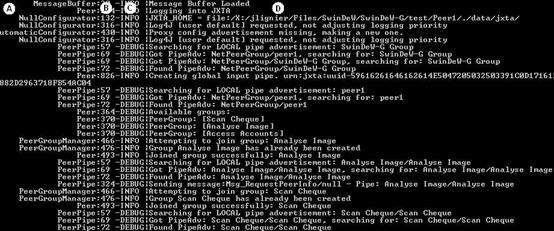
Fig. 7. Command window output from a SwinDeW-G peer
The output of SwinDeW-G is divided into four columns. These columns are labelled in the image shown in Fig. 7 and are described below.
- The java class file that the message is being generated in. All the source files for SwinDeW-G are located in the ‘src’ directory and can be matched against the class names in this column. Note: not all the message in the output window originate from SwinDeW-G some are also from JXTA and Globus.
- This is the line number of the class file that the message is being generated on.
- The type of message that is being generated. There are four types of message. These are Debug, Info, Error and Fatal.
- The output message. The describes a certain actions that has taken place within SwinDeW-G
6.2. Log File
All the output that is displayed in the command window is also output to a text file. This text file can be found in the … directory under the name … . If unknown errors occur it is recommend to email the generated log files to the SwinDeW-G development team.
Note: The log files are emptied every time a peer loads. So each log file only contains the output of the last peer execution.
7. Test Case
An example workflow has been included in the SwinDeW-G distribution to demonstrate the prototype’s functionality. The file that contains this workflow can be located under ‘clients/bank_workflow.xml’. The following section describes how to upload and enact this process along with a description of the workflow process.
7.1. Workflow Process Description
Fig. 8 is a description of the workflow that we will use in our test case.
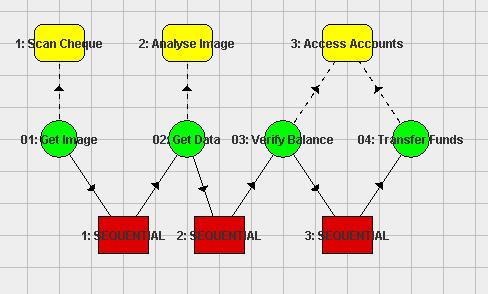
Fig. 8. Cheque Processing Workflow (A Large Number of Cheques)
This is a graphical representation of the workflow contained in ‘bank_workflow.xml’. It is intended as a simplified version of how cheques are processed in a bank once they have been received. A description of the different elements in the diagram is provided bellow.
- Yellow boxes – These are the capabilities that represent the work that will be performed when a task is enacted. These capabilities are generally able to be performed on a diverse set of peers as defined in their ‘capabilities.xml’ file.
- Green circle – These are the tasks of the workflow. In this workflow they execute one after the other in sequential order until the end is reached. When each task is enacted its capability is also accessed.
- Red rectangle – This is the logic of the workflow. This controls how the process will flow from one task to the next.
7.2. Launch peers
To start with we need to load 3 peers on which the workflow will be enacted. To do this open the SwinDeW-G client and open the ‘Peer Launcher’ tab. Use the following parameters in the input fields:
- Number of peers – 3
- Using IP address – Local machine IP address. This can be found by clicking the ‘Get local IP’ button
- Beginning with port number – This should be left as default unless one of the ports that will be assigned (7000 – 7005) is already in use.
- Peers’ main directory – By default the ‘peer_data’ directory under ‘clients’ can be used. If you wish the peer data to be stored elsewhere then specify this directory here.
- Peers’ default data directory – This will be the ‘defaults’ directory under ‘clients’.
Once these parameters have been entered then press the ‘Create peers’ button.
Three command windows should now open which will show each peer loading and joining groups according to their capabilities.
7.3. Upload workflow
The workflow now needs to be uploaded onto one of the peers. It does not matter which peer we use because when a SwinDeW-G peer receives a workflow it will automatically distribute it amongst its neighbours. In this example we will upload the workflow to peer1.
First, open the SwinDeW-G client and open the ‘Client’ tab. Now enter the URI of peer1 and click ‘Connect’. Next, browse to where ‘bank_workflow.xml’ is located. Once this is done, click the ‘Load’ button.
In peer1’s command window you should now see the workflow being loaded and distributed to peer’s 2 and 3.
7.4. Enact process
Processes should only be enacted on peers that have the first capability in the workflow. This does not affect our example as all three peers have all the capabilities of the workflow.
To enact the process first enter the process name “Cheque Processing” into the text box. Then click the ‘Enact’ button. Be sure that the client is still connected to peer1.
In the command window for each of the peers you should see the process enacting from start to finish.
7.5. Further Experimentation
To further experiment with the functionality of SwinDeW-G you may want to run this test using additional peers. Also it is possible to limit the capabilities that each peer has so that certain tasks in the workflow can only enact on some of the peers.
8. Some Related Publications
· J. Chen and Y. Yang, Adaptive Selection of Necessary and Sufficient Checkpoints for Dynamic Verification of Temporal Constraints in Grid Workflow Systems. ACM Transactions on Autonomous and Adaptive Systems (TAAS), accepted, 2007, to appear, [PDF].
· Y. Yang, K. Liu, J. Chen, J. Lignier and H. Jin, Peer-to-Peer Based Grid Workflow Runtime Environment of SwinDeW-G, Proc. of 3rd International Conference on e-Science and Grid Computing (e-Science2007), Bangalore, India, Dec. 2007, [PDF].
· J. Yan, Y. Yang and G. K. Raikundalia. SwinDeW - A Peer-to-peer based Decentralized Workflow Management System. IEEE Transactions on Systems, Man and Cybernetics, Part A, 36(5):922-935, 2006.